吴恩达《机器学习》课程总结(17)大规模机器学习
本文共 619 字,大约阅读时间需要 2 分钟。
17.1大型数据集的学习
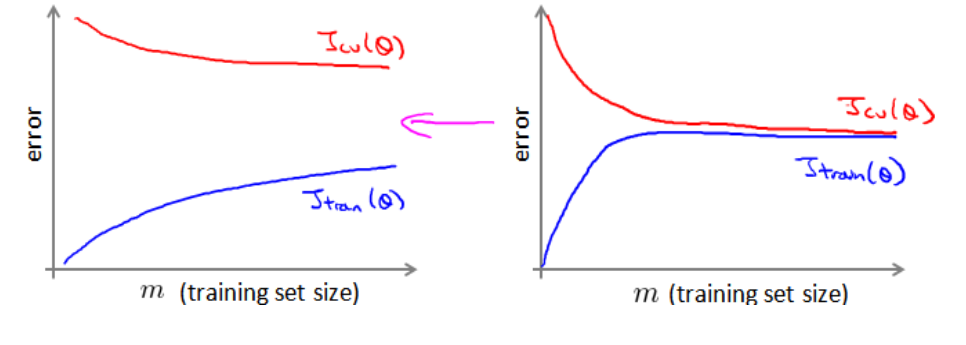
首先通过学习曲线判断是否增大数据集有效:
高方差时(交叉验证集误差减去训练集误差大时)增加数据集可以提高系统。下图中左图增加数据集有效,右图无效。
17.2随机梯度下降法
随机梯度下降法是只使用一个样本来迭代,其损失函数为:
![]()
迭代过程为:
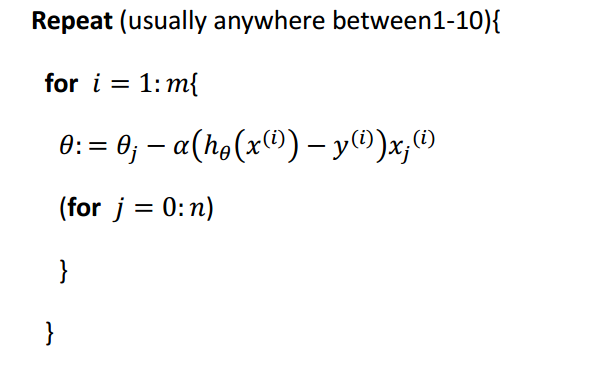
特点:
(1)计算量小,迭代速度快;
(2)在最小值附近徘徊,无法求得最小值。
17.3小批量梯度下降
每次迭代所使用的样本数介于批量梯度下降法和随机梯度下降法之间,通常是2-100。
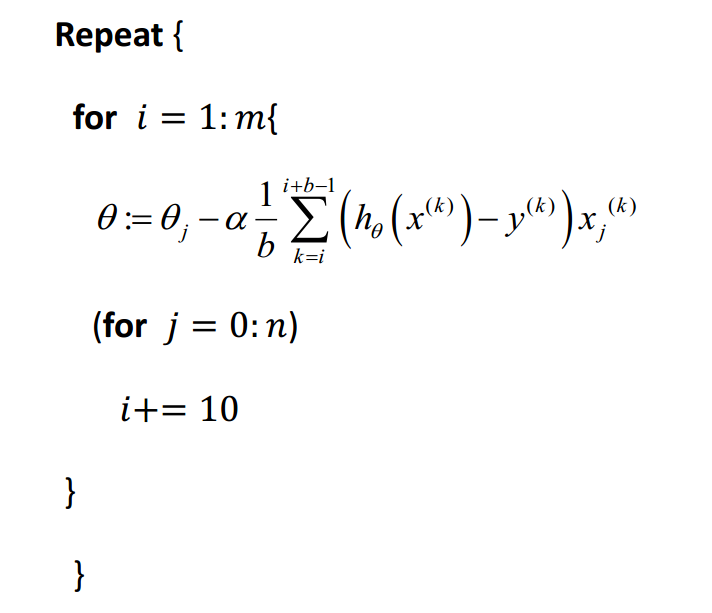
17.4随机梯度下降收敛
(1)对于批量梯度下降法而言,每次迭代求其代价函数的计算量太大,不现实;
(2)对于随机梯度下降法而言,每次迭代计算代价函数,然后经过x次迭代之后求x次代价函数的平均值,然后将该值与迭代次数绘制到图上。
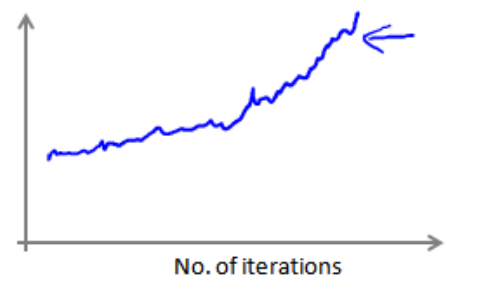
(3)如果得到的图颠簸切看不到明显减少的函数图像,如下图中蓝色所示,可以增加α来时函数更加平缓,如下图红色所示,如果是洋红色可能说明模型本身有问题。
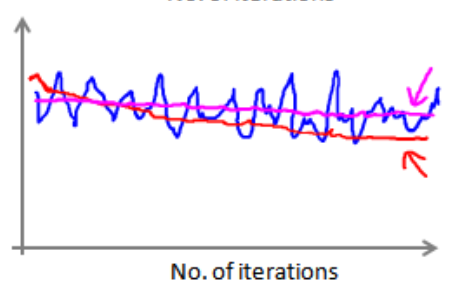
(4)如果出现代价函数随迭代次数的增加而增加,学习率α可能需要随着迭代的次数而减小:
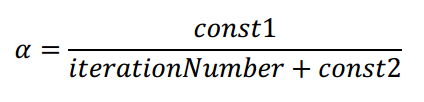
17.5在线学习
常用于网站中,有连续的数据流可供模型来学习,与传统的模型学习没有什么大的差别;如果有连续的数据集,这种方法着重考虑。

17.6映射简化和数据并行
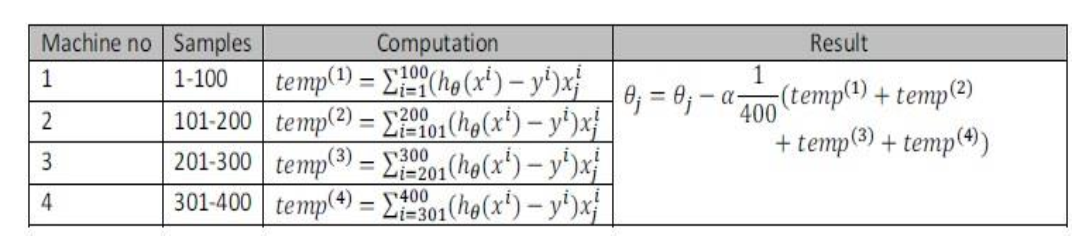
如果任何学习算法能够表达为对训练集的函数求和,便可以分配到多台计算机中计算子集,然后再求和(也叫做映射简化mapreduce),如下所示(其实就并行计算):
转载地址:http://xwjta.baihongyu.com/
你可能感兴趣的文章
阿里感悟(十八)- 应届生Review
查看>>
话说模式匹配(5) for表达式中的模式匹配
查看>>
《锋利的SQL(第2版)》——1.7 常用函数
查看>>
jquery中hover()的用法。简单粗暴
查看>>
线程管理(六)等待线程的终结
查看>>
spring boot集成mongodb最简单版
查看>>
DELL EqualLogic PS存储数据恢复全过程整理
查看>>
《Node.js入门经典》一2.3 安装模块
查看>>
《Java 开发从入门到精通》—— 2.5 技术解惑
查看>>
Linux 性能诊断 perf使用指南
查看>>
实操分享:看看小白我如何第一次搭建阿里云windows服务器(Tomcat+Mysql)
查看>>
Sphinx 配置文件说明
查看>>
数据结构实践——顺序表应用
查看>>
python2.7 之centos7 安装 pip, Scrapy
查看>>
机智云开源框架初始化顺序
查看>>
Spark修炼之道(进阶篇)——Spark入门到精通:第五节 Spark编程模型(二)
查看>>
一线架构师实践指南:云时代下双活零切换的七大关键点
查看>>
ART世界探险(19) - 优化编译器的编译流程
查看>>
玩转Edas应用部署
查看>>
music-音符与常用记号
查看>>